The main differences between data analysis and data analytics are that in the former, the focus is on providing information about a subject, breaking it down, and gaining a better understanding of it. This is done through a comprehensive description of a given studied plight, proposing forecasts, and mathematical models. In contrast, the latter is developed based on predictions, changes, or projections about the model in the future.
The case shown below is an example of data analysis that helps to describe and understand plasma physics, which is a common and relevant problem for future energy research.
TARGETS
Noisy or contaminated information is of interest because devices such as voice recognition systems or any device that collects information aim to eliminate such noise.
OUTCOMES
“By using mathematical models, the original signal was cleaned and regenerated, revealing hidden patterns in the data and enabling the prediction of the dynamics of this physics phenomenon.”
PROJECT DURATION
The project lasted for 4 months, starting with an understanding of the noise problem caused by interference in the sensors. After analyzing the data, the results were shared, and an algorithm capable of creating future emissivity profiles was built. The data was cleaned, and an accurate prediction model was generated.
First step
The dataset was obtained through scraping methods, pulling information from scientific articles and previous investigations. The shape of mathematical models was surmised by comparing the dataset and experimental data. The model was then tested on the dataset.
Example of one of sources of scraping made
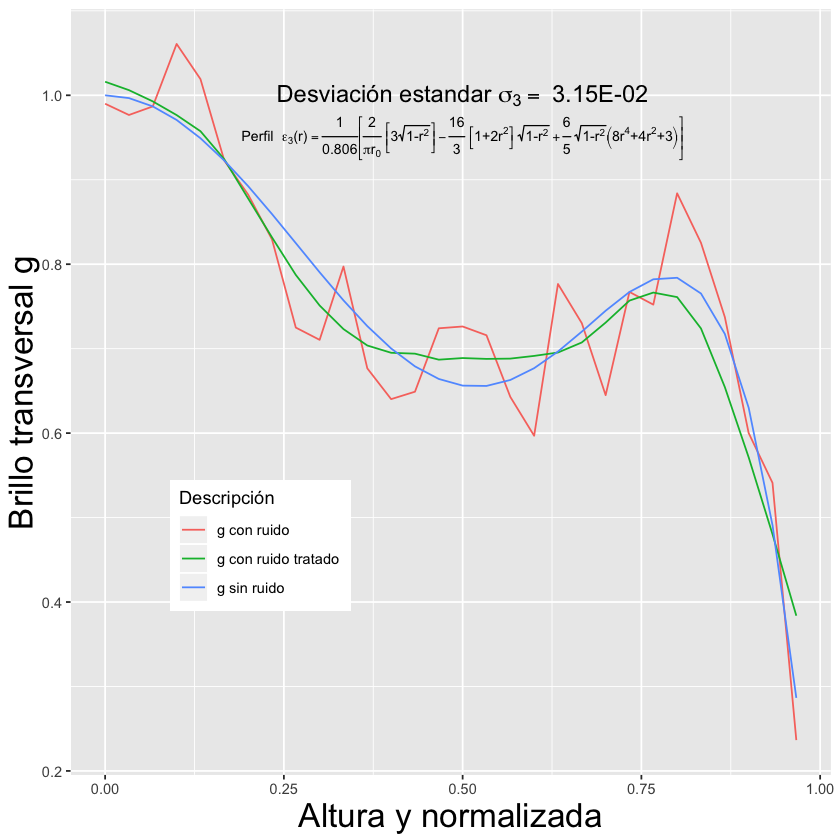
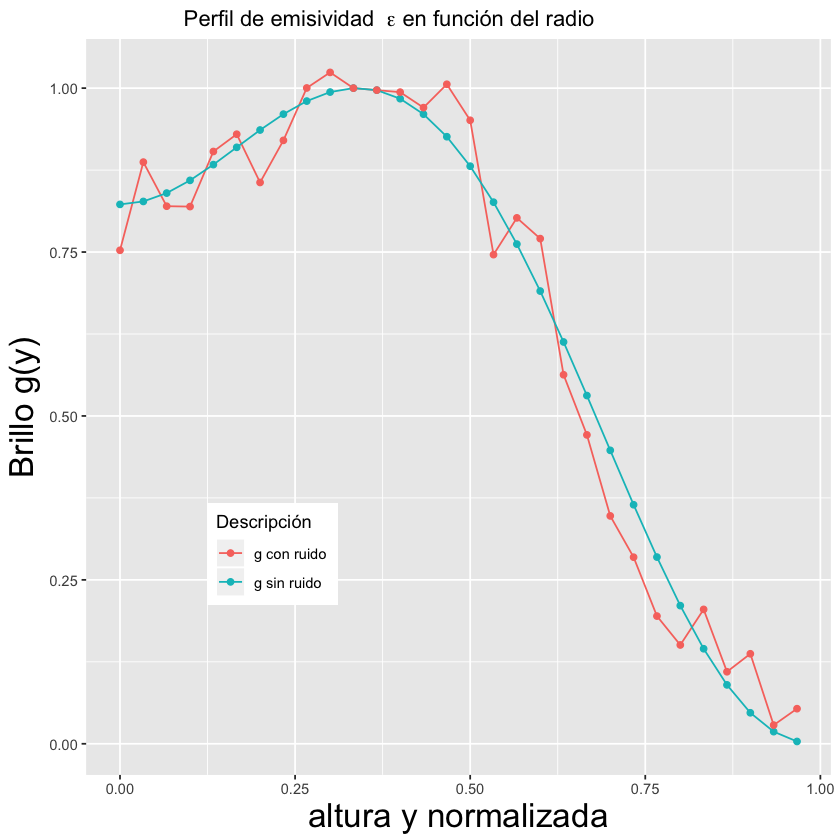
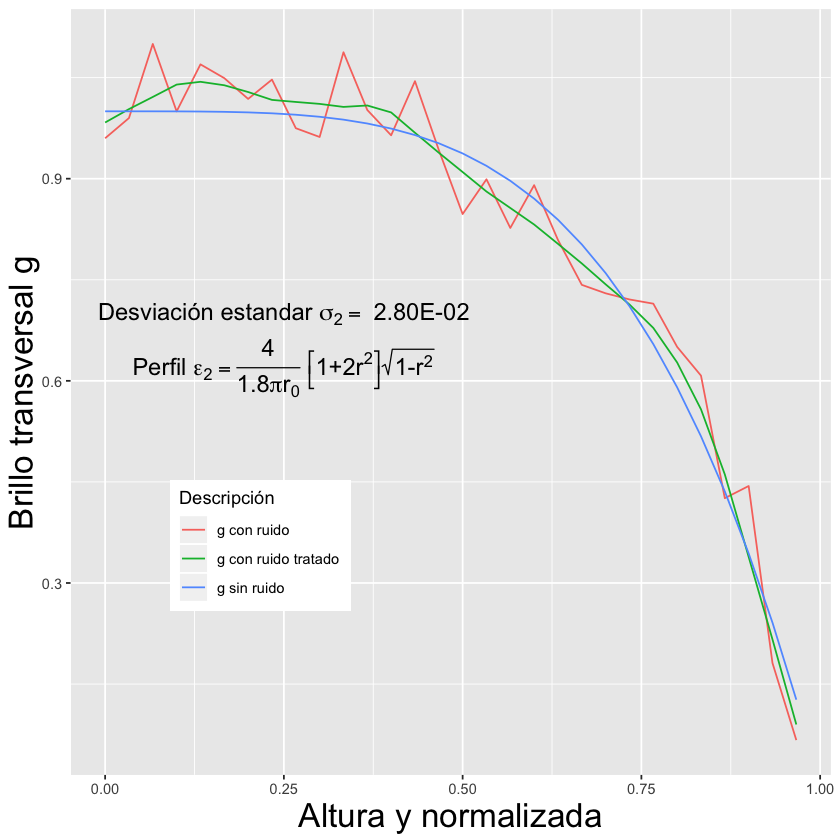
Mathematical and statistical models were developed to estimate the emissivity profile, which is a crucial mathematical tool to understand plasma. To measure both the real and hidden information, machine learning algorithms were used to fix the signals.
Thanks to the creation of the model, it was possible to tune the parameters, leading to an improved understanding and limitations of manipulating nuclear energy. Below are the enhanced results obtained based on the parameter settings
How much did the model improve?
By adjusting the parameters, the model reduced errors in data collection, which is the difference between the captured or measured information and the original data. This resulted in savings in time and costs for tuning the measuring apparatus.
Are you decided to improve production processes, getting profitable advantages with hidden data?